2023年10月19日に行なわれたOpenTelemetry Meetup 2023-10にいってみました。
楽しかったので感想を書きます。
なお、本eventは
- 会場/配信: CARTA HOLDINGS社
- 飲み物: Splunk社
の協賛で行なわれたそうです。ありがとうございます🙏
リアルのeventはとても久しぶりでconnpass上ですと前回参加したのは2019年のKubernetes Meetup Tokyo #23でした。
オープニング
本eventが開催されたのは"機運がたかまってきた"からということでした。
自分がOpenTelemetryに興味をもったのは、tokio-rs/tracing-opentelemetry crateをみかけたのがきっかけでした。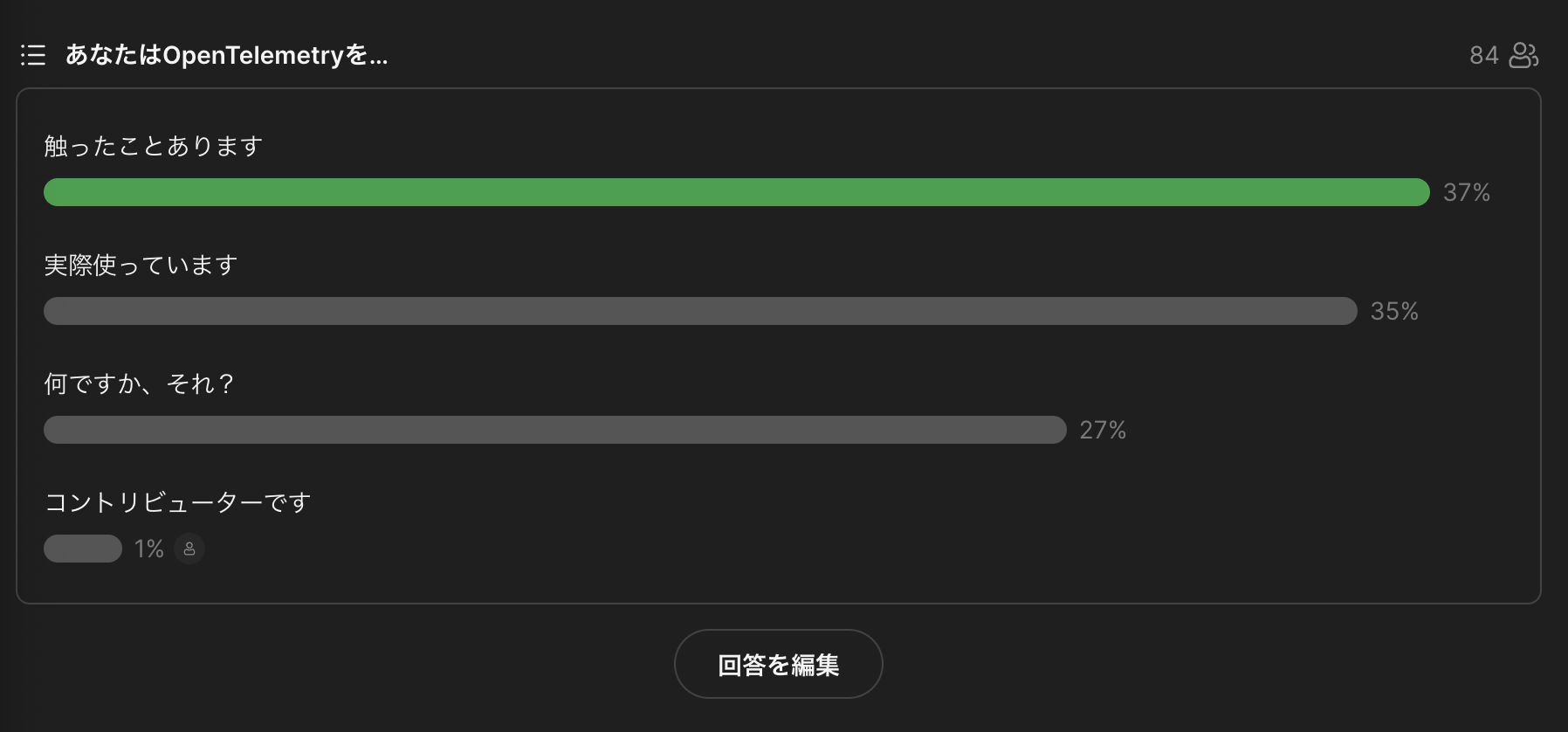
最初にアイスブレイクでOpenTelemetryの使用に関する質問がありました。
Eventに参加されるだけあって、利用されている方々が多かったです。
自分は気が大きくなってopentelemetry-rustのgood first issueをやったし、コントリビューターでしょと回答してしまいました
OpenTelemetryのここ4年弱の流れ
スピーカー: 山口能迪さん(@ymotongpoo)
2022年に発表されたOpenTelemetryのこれまでとこれから を今回のevent用に更新/まとめていただいた内容でした。
自分がOpenTelemetryについて知ったのは2022年だったので、歴史的経緯の説明は非常にありがたいです。
OTLPについても自分はprotobuf定義してあって、言語に依らずに data構造定義されていて便利だなくらいにしか思っていなかったのですが、それができた問題意識等の説明がありました。
2023年10月の各言語の実装状況では、Javaがtrace,metrics,logでstableとなっており、実装が先行しているそうです。
C/C++も3 signalでstableとなっており、さすが強いと思いました。 Rustについてはopentelemetry-rustをみている限り、現在絶賛実装中という感じです。
また、エコシステム(Splunk, Elastic, Honeycomb, Dynatrace, Sentry,...)でもOTLPのサポートが増えてきているそうです。
うれしいですね。
これは完全に知らなかったのですが、Profilingを標準化する試みもあるそうです。
OpenTelemetryでprofilingも扱うことができるようになるのは夢があると思いました。
また、Opentelemetry Enhancement Proposal(OTEP)というrepositoryを知れました。これからPRをwatchしていこうと思います。
OTel導入事例1: ジョインしたチームのマイクロサービスたちを再計装した話
スピーカー: 逆井(さかさい)啓佑さん
参画されたプロダクトにOpenTelemetryのtraceを計装された点についてのお話でした。
再計装というのは一部、前任者の方が導入された点を引き継いだという文脈でした。
現状、自分はcontrib版のopentelemetry-collectorを利用しているのですが、productionでは必要なcomponentのみを備えたものをbuildするほうがよいというアドバイスがありました。
実際に利用しそうなreceiverやprocessorのあたりがついてきたので、自前のcollector作成にも取り組んでみようと思いました。 Rustならこの点はfeatureで制御できそうで、rustでcollectorが実装される日を夢見ています。
実際にチームに展開する際の取り組みやlocalの切り分け等、とても参考になるお話でした。
また、Span Metrics Connectorは知らなかったので、調べてみたいと思いました。
ヘンリーにおける可観測性獲得への取り組み
スピーカー: 株式会社ヘンリー Nabeoさん
複雑なdomainを背景にOpenTelemetryを導入する際の検討について共有いただいた話。
こういう案試したけど、こうでしたという話はひたすら参考になるので非常にありがたいです。
opentelemetry-collectorをsidecarとして利用する方法にもメリット/デメリットあるので、うまいことトレードオフするのが自分の課題だったので、とても参考になりました。
現状はsidecarでcollectorを動かしていますが、リソースの有効利用の観点からdeploymentかdaemonsetもありかなと現状では考えています。
ただ、daemonsetでcollector動かすと、特定のtelemetryのrewrite系の処理がメンテしづらくなりそうだなと懸念していたりします。
Q&A
発表後にslidoでのQ&Aがありました。
質問は30以上はあったかと思います。
slidoの質問のURLの取得方法がわからなかったので、自分がメモした範囲でSSを掲載します。
Collectorのメリット

Collectorを導入するメリットはいろいろあると思います。
識者の方々の回答としてはprocessorを利用できる点があげられていました。
逆にいうとcollectorというcomponentを一つ増やす以上はcollectorの機能を使い倒さないと管理コストだけ増えることになるので、collectorの理解度をあげないとなと思いました。
Observabilityの費用対効果

個人的にはやらないという選択肢はないと思っていたのですが、こういった問題意識は忘れずに、運用での問題調査や改善でopentelemetry導入して正解でしたね、にしないといけないと思っています。 いうのは簡単だが、果たして
Sidecar collectorのCPU

Cloud Runは利用したことがないのですが、collectorへのリソース割当は自分も悩ましく思っています。
これは実際に計測するしかないので、collectorを計測できるようにするのが次の課題だと思っています。
結局、トレースとログは何が違うのですか?

回答: "同じです"
補足: samplingされていて、water fallになっていて、latencyに関する情報をもっているのがtrace。
任意の情報をもっているのがlog。
なにごとも言い切れるのはすごいと思ってしまう。
Realtime User Monitoringについて

実装が公開されているのでそれをまずは見てみましょうということでした。
Frontの話ですがここも追っていかなければ..
コストの抑え方

Samplingの話でした。
Traceの全件取得は実際問題現実的でないので、samplingは必須という認識でした。
自分はhead samplingしてapplicationへのperformanceへの影響も抑えたいと考えていたのですが、errorの補足の観点からはtail samplingしたくなるので、ここも課題です。課題しかない
Metricsのexamplarの使い方

これは自分が質問しました。
答えとしては、metricsとtraceを紐付ける機能ということでした。
例えばCPU使用率のmetricsが高くなった場合に相関するtraceを紐付けるといったことが可能となるようです。
これができてはじめて、traceとmetricsを統一して扱うメリットが得られると思うので、調べて実装していきたいです。
時間の関係で回答は得られませんでしたが、semantic conventionsにおけるschema_urlの利用例も気になるところでした。
まとめ
楽しかったので次回も参加してみたいです。
Rustが一度も言及されなかったので、Rust + OpenTelemetryをがんばっていきたいと思いました。